MOMENT: A FAMILY OF OPEN TIME-SERIES FOUNDATION MODELS
Mononito Goswami1 Konrad Szafer*1 Arjun Choudhry*1 Yifu Cai1 Shuo Li2 Artur Dubrawski1
1Carnegie Mellon University, 2University of Pennsylvania
* Equal contribution
2024
We introduce MOMENT, a family of open-source foundation models for general-purpose time-series analysis. Pre-training large models on time-series data is challenging due to (1) the absence of a large and cohesive public time-series repository, and (2) diverse time-series characteristics which make multi-dataset training onerous. Additionally, (3) experimental benchmarks to evaluate these models, especially in scenarios with limited resources, time, and supervision, are still in their nascent stages. To address these challenges, we compile a large and diverse collection of public time-series, called the Time-series Pile, and systematically tackle time-series-specific challenges to unlock large-scale multi-dataset pre-training. Finally, we build on recent work to design a benchmark to evaluate time-series foundation models on diverse tasks and datasets in limited supervision settings. Experiments on this benchmark demonstrate the effectiveness of our pre-trained models with minimal data and task-specific fine-tuning. Finally, we present several interesting empirical observations about large pre-trained time-series models.
The Time-series Pile
We compiled a large collection of publicly available datasets from diverse domains into the Time Series Pile. It has 13 unique domains of data, which includes 20.085 GB worth of 13M unique time series and 1.23 billion timestamps (including channels). The data has been collated from more than 5 task-specific, widely-used public repositories resulting in a large number of time series spanning diverse domains, and time series characteristics such as lengths, amplitudes, and temporal resolutions. Some details about these public repositories are as follows:
-
Informer long-horizon forecasting datasets (Zhou et al., 2021) is a collection of 9 datasets that are widely used to evaluate long-horizon forecasting performance: 2 hourly and minutely subsets of the Electricity Transformer Temperature (ETT), Electricity, Traffic, Weather, Influenza-like Illness (ILI), and Exchange-rate.
-
Monash time series forecasting archive (Godahewa et al., 2021)) is a collection of 58 publicly available short-horizon forecasting datasets with a total of over 100K time series, spanning a variety of domains and temporal resolutions.
-
UCR/UEA classification archive (Dau et al., 2018) comprises of 159 time series datasets which are frequently used to benchmark classification algorithms. These datasets belong to seven different categories (Image Outline, Sensor Readings, Motion Capture, Spectrographs, ECG, Electric Devices, and Simulated Data), and vary substantially in terms of the number of classes and the size of the training set.
-
TSB-UAD anomaly benchmark (Paparrizos et al., 2022b) is a recent collection of 1980 univariate time series with labeled anomalies from 18 anomaly detection datasets proposed over the past decade. This collection includes both synthetic and real-world time series originating from a wide range of sources such as the human body, spaceships, environment, and web serves.
General Time-series Pre-training
Unlike text and images, which have largely consistent sampling rates and number of channels, time-series frequently vary in their temporal resolution, number of channels, lengths, and amplitudes, and sometimes have missing values. As a result, large-scale mixed dataset pre-training is largely unexplored. Instead, most methods are trained on a single dataset, and transferred across multiple datasets, but with modest success.
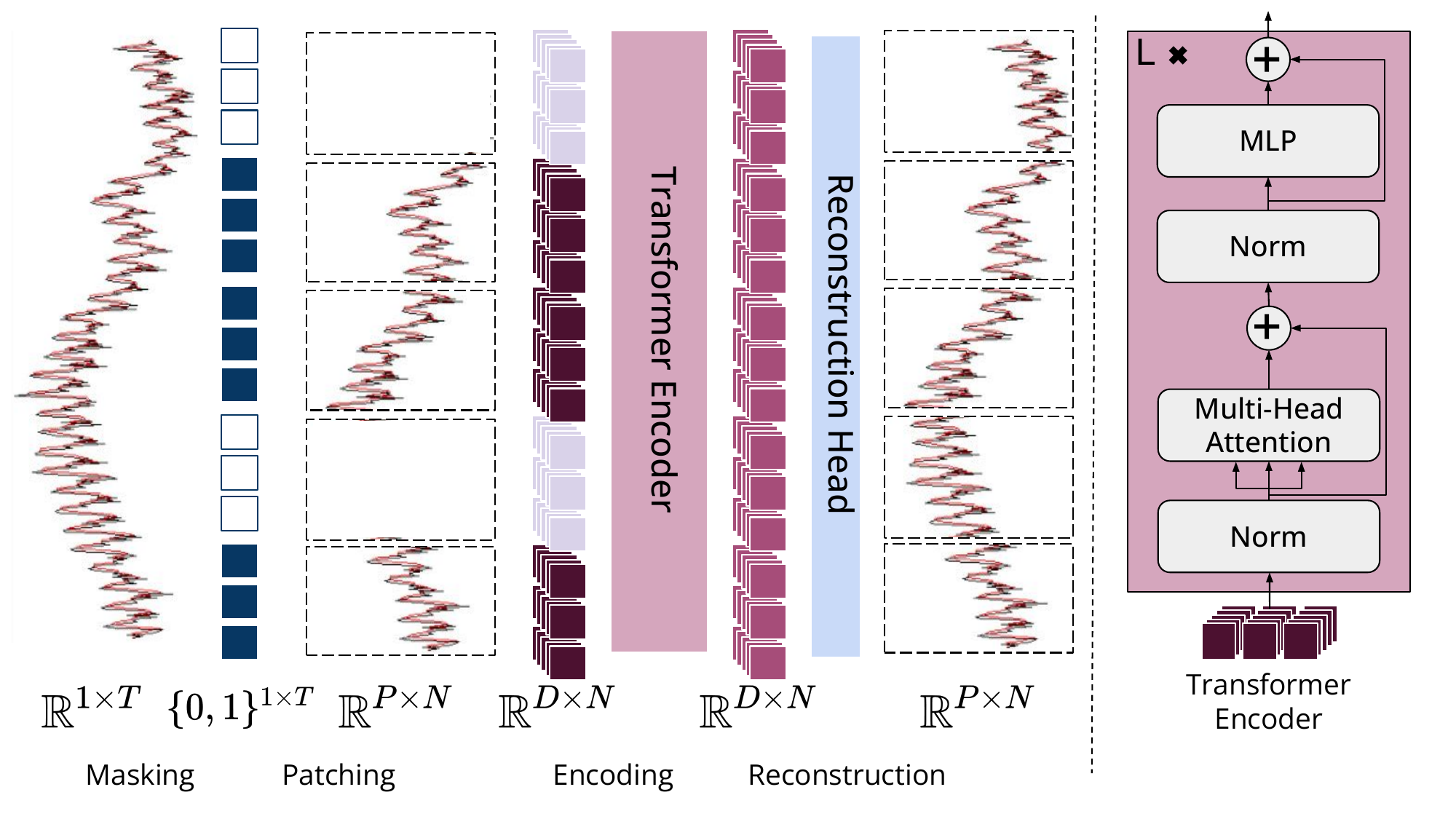
Overview of MOMENT pre-training procedure and architecture.
Holistic Multi-task Evaluation
Comprehensive benchmarks to evaluate time-series foundation models on diverse datasets and tasks are in their nascent stages. To evaluate MOMENT, we build on the multi-task time-series modeling benchmark first proposed by Wu et al. [2023] along multiple dimensions. For each of the 5 time-series modeling tasks, namely, short- and long-horizon forecasting, classification, anomaly detection, and imputation we evaluate MOMENT against (1) both state-of-the-art deep learning as well as statistical baselines, on (2) more task-specific datasets, (3) using multiple evaluation metrics, (4) exclusively in limited supervision settings (e.g., zero-shot imputation, linear probing for forecasting, unsupervised representation learning for classification).
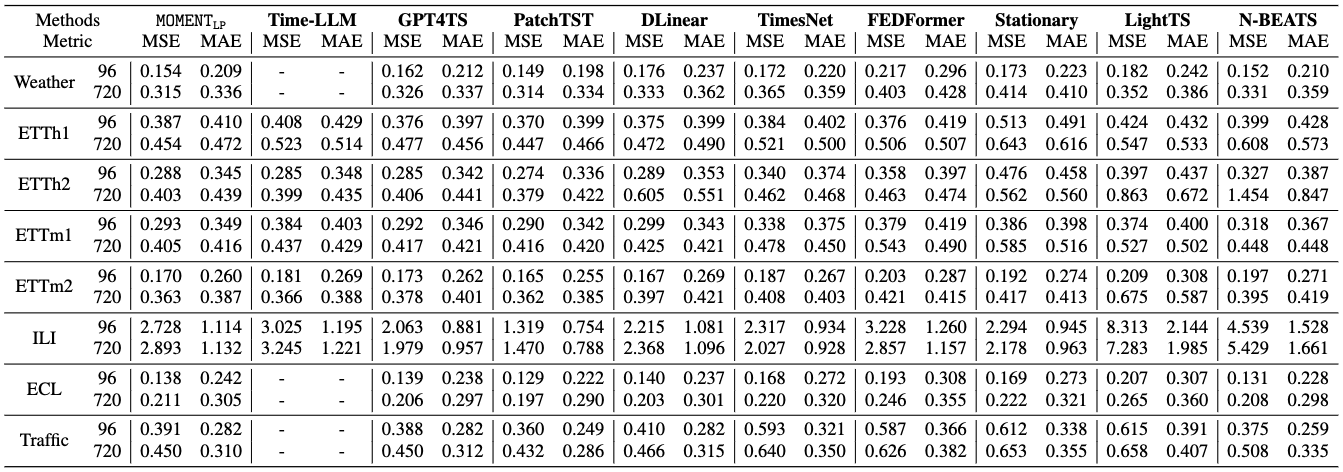
Long-term forecasting performance measured using Mean Squared Error (MSE) and Mean Absolute Error (MAE).

Zero-shot short-horizon forecasting performance on a subset of the M3 and M4 datasets measured using sMAPE.

Classification accuracy of methods across 91 UCR datasets. Methods with mean and median accuracy higher than MOMENT are in **bold**.

Imputation Results. MOMENT with linear probing achieved the lowest reconstruction error on all ETT datasets.
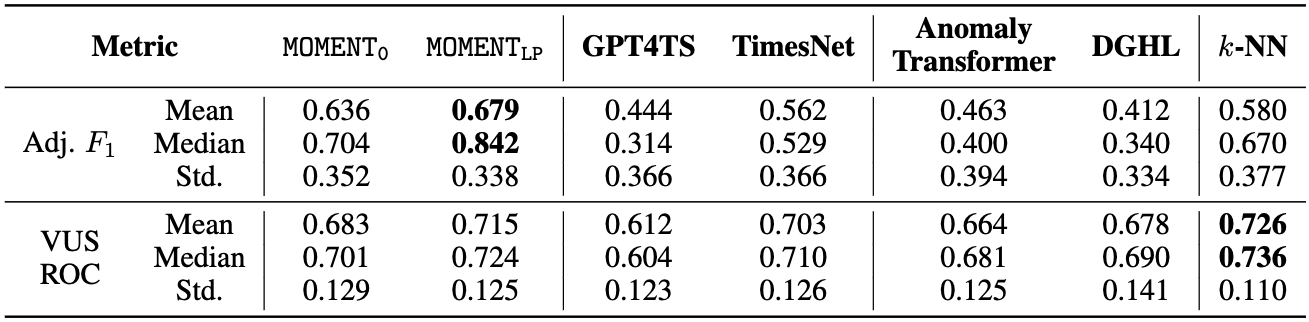
Anomaly detection performance averaged over 44 time-series from the UCR Anomaly Archive.
BibTeX
@inproceedings{goswami2024moment,
title={MOMENT: A Family of Open Time-series Foundation Models},
author={Mononito Goswami and Konrad Szafer and Arjun Choudhry and Yifu Cai and Shuo Li and Artur Dubrawski},
booktitle={International Conference on Machine Learning},
year={2024},
abstract={We introduce MOMENT, a family of open-source foundation models for general-purpose time-series analysis. Pre-training large models on time-series data is challenging due to (1) the absence of a large and cohesive public time-series repository, and (2) diverse time-series characteristics which make multi-dataset training onerous. Additionally, (3) experimental benchmarks to evaluate these models, especially in scenarios with limited resources, time, and supervision, are still in their nascent stages. To address these challenges, we compile a large and diverse collection of public time-series, called the Time-series Pile, and systematically tackle time-series-specific challenges to unlock large-scale multi-dataset pre-training. Finally, we build on recent work to design a benchmark to evaluate time-series foundation models on diverse tasks and datasets in limited supervision settings. Experiments on this benchmark demonstrate the effectiveness of our pre-trained models with minimal data and task-specific fine-tuning. Finally, we present several interesting empirical observations about large pre-trained time-series models. Our code is available anonymously at anonymous.4open.science/r/BETT-773F/.}
}